Multi-Agent Frameworks for LLM-Powered Deep Research Systems

Large Language Models (LLMs) have evolved from simple text predictors into sophisticated research agents capable of scouring the web, running code, and piecing together knowledge. With the introduction of features like ChatGPT’s browsing mode and code interpreter, OpenAI and others have shown that an LLM can be more than a chatbot — it can be an orchestrator of tools that performs deep, multi-step research in real-world environments. This post dives into the passionate technical details of how LLMs like ChatGPT are structured and orchestrated to tackle complex research tasks on the live web. We’ll break down the LLM framework, explore how queries get decomposed and routed to specialized “agents” (reasoning, searching, browsing, coding), use analogies to clarify concepts, and examine how reinforcement learning ties it all together with outcome-driven training. Along the way, we’ll reference emerging systems (OpenAI’s Deep Research, GAIR’s DeepResearcher, Google’s Gemini Deep Research, xAI’s Grok3) and highlight the key architectural insights that enable planning, self-reflection, cross-validation of sources, and honesty about uncertainty.
From Static Knowledge to Active Research Agents
Traditional LLMs like early GPT-3 were confined to their training data — they produced answers based on static knowledge. If asked about recent events or detailed data, they either hallucinated or apologized for not knowing. The latest generation of LLMs breaks free of that limitation by actively retrieving information in real time. Think of the difference like a research librarian versus an encyclopedia: the librarian (our LLM agent) can search new books, fetch relevant documents, analyze data and then answer, whereas an encyclopedia (a static model) can only repeat what it already contains.
This shift gave birth to what we call LLM-based research agents. ChatGPT’s “Browsing” mode and similar features in other models turn the once self-contained LLM into an executive agent that can perform web searches, read content, and even execute code. Such an agent receives a user’s complex query and decomposes it into sub-tasks, much like a human researcher would break a big question into smaller questions. It might decide: “First, search for X; then read about Y; then calculate Z; finally, summarize the findings.” Each sub-task is handled by a specialized component or tool, but the LLM remains the brain, coordinating these steps.
One useful analogy is a detective with a task force. The LLM detective plans the investigation and asks a “web search expert” to gather clues, a “browsing agent” to read through files or websites, and a “code analyst” to crunch numbers if needed. The detective then analyzes all the clues and writes up the case report (the answer). This orchestration happens behind the scenes in seconds, but it’s built on a careful architectural design.
Anatomy of a Deep Research LLM Framework
To enable this kind of complex behavior, modern LLM research systems adopt a multi-agent framework within a single unified model. In practice, this often doesn’t mean separate AI models, but rather distinct functional phases or modules orchestrated by the LLM. Here are the key components in the architecture, as exemplified by OpenAI’s ChatGPT with Deep Research and similar systems:
- LLM Reasoning Agent (Brain): The core LLM that interprets the query, maintains the chain-of-thought, and decides what action to take next. It plans the research steps (“think first, then act”) and keeps track of information found so far. This is ChatGPT itself “thinking” out loud (in hidden prompt or internal state) about how to answer.
- Search Agent: An interface to a web search API (like Bing or Google). When the LLM decides to
search, it formulates a query and sends it out. The search agent returns a list of results (titles, snippets, URLs) relevant to that query. This is akin to asking a librarian to quickly find books or articles on a topic. - Browsing Agent: A web browser automation that can fetch a page from a given URL and either read it entirely or extract relevant parts. The LLM uses this when it needs more than just a snippet — e.g., opening a Wikipedia page or a news article to find specific detailsfile-cmgfeoxcx9jrts5tziqyzj. The browsing agent might return the full text or a parsed chunk of the page for the LLM to read.
- Code Interpreter (Analysis Agent): An embedded coding environment (often Python) where the LLM can write and execute code. This is used for tasks like data analysis, running calculations, or even generating visualizations (graphs, charts) from data. OpenAI’s Code Interpreter (now an official ChatGPT feature) exemplifies this — the LLM can decide to write a Python script to, say, parse a table from a webpage or perform statistical analysis, and then run it.
- Memory/Context: While not a separate tool, it’s crucial to note the LLM maintains a context of all prior steps — the conversation history and intermediate results (sometimes called the “scratchpad”). This is how the model “remembers” facts found earlier and can use them in subsequent reasoning.
At the center is the LLM itself, which orchestrates these components like a conductor. The LLM’s prompt is structured (by the system or the agent framework) to include a format for Thoughts (the LLM’s reasoning) and Actions (calls to tools), often following the ReAct paradigm. For example, the LLM might output a thought: “I should search for the composer of Gloria in D Major.” followed by an action: <search> "composer of Gloria in D Major". The system sees the <search> tag and invokes the Search agent with that query. Once results come back, the LLM incorporates them (the “Observation”) into its context and continues reasoning.
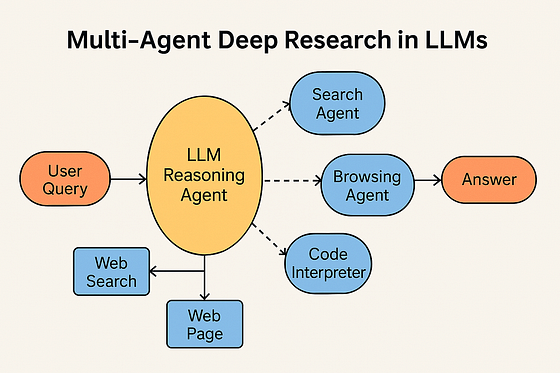
What does this architecture look like as a whole? Imagine a flow where the user’s question enters from one side and the final answer comes out the other, with the LLM and various tool calls in between. The diagram below illustrates a typical orchestration pipeline for an LLM-based research agent:

Multi-agent orchestration in an LLM research agent. The user’s query enters (left), and the central LLM (yellow “oracle”) plans a series of actions. It can call a web search tool, a specialized research database, or other knowledge sources (blue ovals). Each tool returns information (dashed lines back), which the LLM uses to decide the next step. After gathering sufficient evidence, the LLM produces the final answer (right). This graph-based design is similar to frameworks like LangChain’s LangGraph, where an agent is defined as a graph of nodes (actions) connected by the logic of the LLM’s decisions.
In OpenAI’s implementation (e.g. ChatGPT browsing), this process is usually serialized (one step at a time), but the principle is the same — the LLM drives the sequence: it thinks → acts (calls a tool) → observes (gets result) → thinks again, and so on, until it decides to output an answer. Crucially, all these steps are learned behaviors or defined via prompt schemas — they are not if/else rules hard-coded by developers, but rather skills imbued into the model via training and prompting.
Step-by-Step Orchestration: Breaking Down a Multi-Hop Query
To make this concrete, let’s walk through how a complex query might be handled. Consider a question: “What is the name of the famous bridge in the birthplace of the composer of Gloria in D Major?” — This is a multi-hop question that requires several steps: find the composer of Gloria in D Major, find that composer’s birthplace, then find a famous bridge in that city. A human might solve it by searching for each piece, and that’s exactly what an LLM agent will do, guided by its internal reasoning plan.

- Planning: The LLM (reasoning agent) parses the question and determines it needs to break the task down. It might internally generate a step-by-step plan (not shown to the user) like: “Step 1: Identify the composer of Gloria in D Major. Step 2: Find the place of birth of that composer. Step 3: Find a famous bridge in that city.”. This plan is essentially the LLM’s chain-of-thought, structured as goals.
- First search action: The LLM now issues an action:
<search>for “composer of Gloria in D Major”. The Search agent executes this web query. Let’s say it returns a snippet about Antonio Vivaldi (who composed a Gloria) and perhaps a Wikipedia link. The LLM reads the snippet: “Antonio Vivaldi wrote at least three Gloria compositions…” – from this it infers Antonio Vivaldi is the composer, and likely the page will mention his birthplace. - Second search (or browse): The LLM’s next thought: “Vivaldi was the composer; I need his birthplace.” It could issue another search: “Antonio Vivaldi birthplace”, or directly browse the Wikipedia result if the snippet already strongly hints at the answer (e.g., snippet says he was born in Venice). In the DeepResearcher example, the agent saw enough to know Venice is the city in question. If not, it would click the Wikipedia link via the Browsing agent to find his birthplace on the page.
- Third search: Now armed with “Venice” as the city, the LLM decides to find a famous bridge in Venice. It issues
<search>for “famous bridge in Venice”. The Search agent returns results, likely including “Rialto Bridge” (a famous bridge in Venice). The LLM captures that Rialto Bridge is the target answer. - Answer: The LLM now has all pieces: Composer = Vivaldi, Birthplace = Venice, Famous bridge in Venice = Rialto Bridge. It formulates the final answer: “The famous bridge is the Rialto Bridge.”
Throughout this process, the user only sees perhaps the final answer and maybe some citation or explanation, but under the hood the LLM took multiple steps, querying and reading information. In fact, OpenAI’s Deep Research mode is explicitly built to conduct such multi-step reasoning and synthesis rather than answering from a single pass. It performs “query interpretation, web scraping & extraction, analysis & synthesis (including using Python), and then report generation”.
To illustrate the orchestration logic, here’s a simplified pseudo-code for how an LLM agent might handle a query with iterative tool use:
def deep_research_agent(query):
# Initialize an empty list of observations (knowledge gathered)
observations = []
while True:
# 1. LLM generates a thought and proposed action based on query and observations so far
thought, action = LLM.plan_next_step(query, observations)
if action.type == "SEARCH":
results = web_search(action.query)
observations.append(("SEARCH", action.query, results))
elif action.type == "BROWSE":
content = fetch_webpage(action.url)
info = extract_relevant(content, query)
observations.append(("BROWSE", action.url, info))
elif action.type == "CODE":
output = run_python_code(action.code)
observations.append(("CODE", action.code, output))
elif action.type == "ANSWER":
answer = action.content # LLM believes it can answer now
return answer # Break the loop and return final answer
# Loop continues, with the LLM considering the new observations in the next iteration.
In this pseudocode, the LLM.plan_next_step is where the magic happens – the LLM looks at the user query and what it’s learned so far (observations from searches or browsing) and decides what to do next. This design is inspired by the ReAct (Reason+Act) loop: the model produces a “Thought” (reasoning) and an “Action” (tool use), then gets an “Observation” from the environment, and repeats. The loop ends when the model produces an ANSWER action, meaning it’s ready to respond to the user.
Notice how the outputs are chained between agents: e.g. the search results become input for the browsing step, the browser’s content becomes input for the LLM’s next thought, and so on. The LLM serves as the routing hub, ensuring that, for example, a search action triggers the search agent and that the returned results are fed into the next reasoning step. In OpenAI’s implementation, this chaining is handled via the API: the model’s response might include a special token or JSON telling the system to invoke a tool, then the system inserts the tool’s output back into the model’s input.
Even more impressive, the LLM is not limited to one cycle of search. It can search in an iterative fashion, refining queries or exploring multiple branches. For instance, when verifying a fact, the agent might do a first search, get some data, then do a second search with additional keywords to cross-check — essentially performing cross-validation across sources. This was seen in the DeepResearcher example where the agent compared two filmmakers by searching each and then specifically searching why one is considered a pioneer. Such validation agents are not separate entities but behaviors of the same LLM agent ensuring consistency and accuracy from multiple sources.
Learning to Research via Reinforcement Learning
Designing the architecture is only half the story — the other half is how the model learns to do all this. Simply prompting GPT-4 to “please search the web as needed” might work in simple cases, but to truly excel at deep research tasks, these systems are increasingly trained with reinforcement learning (RL) on top of supervised behavior cloning. OpenAI’s Deep Research model and GAIR-NLP’s DeepResearcher are prime examples: they use end-to-end RL training in a real web environment to teach the agent how to plan, search, and gather information effectively.
How does this reinforcement learning setup look? In DeepResearcher (Zheng et al., 2024), the authors train an LLM agent on a variety of open-domain questions. The agent’s only reward comes from the final outcome — essentially, it gets a high reward if it answers correctly, and a low (or negative) reward if it’s wrong or if it produces an invalid output. This outcome-based reward (for example, measured by an F1 score comparing the agent’s answer to the ground-truth answer) means the model isn’t explicitly told which intermediate steps are right or wrong; it has to figure out a successful strategy through trial and error. If searching twice and then reading Wikipedia yields the correct answer, the final reward reinforces all the actions in that trajectory. If the agent wanders to irrelevant pages and answers incorrectly, it gets a low reward, signaling that those actions were not fruitful.

Training an agent like this in a real web environment is challenging. The agent has to cope with all the messy realities of the internet — irrelevant results, varying webpage structures, potential errors or blocked pages — and still learn an optimal strategy. The DeepResearcher work had to implement solutions for things like search API rate limits, parsing heterogeneous pages, and avoiding getting trapped by noise. Over time, with enough training (and likely millions of simulated queries), the agent learns robust behaviors such as:
- Formulating multi-step plans: Without being explicitly programmed, the RL-trained agent starts to exhibit a planning behavior — writing out step-by-step approaches in its chain-of-thought before executing, which helps it navigate complex questions systematically.
- Cross-verifying information: The agent learns that checking multiple sources can lead to higher accuracy (and thus higher reward). For example, it might search for a statement, then search again for a related detail to confirm the first source, merging information for a more reliable answer.
- Self-reflection and redirection: If an initial search comes up short or off-target, the agent can notice this (perhaps by an internal confidence or by recognizing irrelevant results) and then refine the query or take a different approach. This is akin to a human researcher realizing “I need to try a different angle.” It’s an emergent skill: the model wasn’t directly told how to self-correct, but the training reward encourages whatever behavior leads to correct answers — often that means backtracking and trying again when stuck.
- Honesty about uncertainty: One fascinating emergent behavior is that the agent learns not to bluff when it doesn’t find a definitive answer. Since making up an answer would likely be incorrect and thus unrewarded, a well-trained research agent will instead respond with uncertainty or a partial answer when appropriate. For instance, if asked for a precise statistic that it cannot find, the agent might say, “I found evidence that it’s a significant portion, but no exact figure, so I won’t speculate.” This aligns with the goal of maintaining factuality and honesty — a crucial aspect for user trust. OpenAI’s system notes highlight that Deep Research models still can hallucinate or err, but they significantly reduce fabrication by grounding answers in retrieved sources.
All these behaviors — planning, cross-checking, reflecting, admitting uncertainty — are essentially side-effects of the training objective. By optimizing for correct, well-supported answers, the agent discovers that it needs to exhibit these traits. This is reminiscent of how AlphaGo’s training via self-play led to unconventional but effective strategies in Go; here the LLM’s training leads to human-like research strategies. In the words of the DeepResearcher team, “the system can formulate plans, cross-validate from multiple sources, engage in reflection, and maintain honesty when it cannot find definitive answers.”file-cmgfeoxcx9jrts5tziqyzj These are precisely the qualities we prize in human researchers, now emerging in AI.
The use of RL also helps in trajectory planning — not explicitly in the sense of the agent computing a path, but by exploring multiple possible action sequences during training and learning which sequences yield the best outcomes. In fact, some implementations run multiple parallel rollouts (trajectories) for the same query and pick the most successful attempt, ensuring that the agent doesn’t miss a solution path due to a random choice. Over thousands of training questions, the agent refines a policy that, say, tends to search and then browse Wikipedia (a high-yield trajectory) rather than, say, directly guessing from memory (a low-yield trajectory).
Beyond OpenAI: An Emerging Ecosystem of Research LLMs
OpenAI isn’t alone in this realm. The idea of LLMs as deep research assistants has caught fire across the AI community, leading to a flurry of systems with similar goals. Google introduced Gemini Deep Research in late 2024, building these multi-step research capabilities into its Gemini AI model. Perplexity AI, known for its LLM search engine, launched Perplexity Deep Research shortly after, and even open-source projects like DeepSeek emerged in response. Each of these systems shares the core concept: an LLM that doesn’t just answer questions, but actively researches them with tool usage and iterative reasoning. The competition has spurred rapid advancements — for instance, OpenAI’s Deep Research is reported to significantly outperform earlier models on tough benchmarks like Humanity’s Last Exam, achieving 26.6% accuracy vs ~9% for older GPT-based models. This indicates how much more capable these research-trained agents are at expert-level questions.
Meanwhile, xAI’s Grok3 (from Elon Musk’s new AI venture) also follows this pattern. Grok3 launched in early 2025 boasting a range of modes like “Deep Search”, “Think”, “Research”, “Analyze Data”, and more — essentially embedding a suite of agent abilities within one model. Users can toggle these modes to let Grok3 dive into real-time information or crunch numbers. Under the hood, Grok likely uses similar orchestration: searching the web, using tools, and iterating through thoughts. The convergence of ideas is apparent: whether it’s OpenAI’s Deep Research, Google’s Gemini, or xAI’s Grok, the state-of-the-art LLMs are all becoming tool-using, self-directed researchers.
It’s worth noting that academia is also exploring this space. The GAIR-NLP DeepResearcher we discussed is one example of a research effort to formalize and improve these agents. There are others like AI2’s ScholarGPT or Meta’s explorations, and frameworks like LangChain are providing the building blocks for anyone to create a mini research agent. We’re witnessing an emerging pattern in AI: moving away from end-to-end one-shot answering, and toward architectures that resemble cognitive workflows — planning, tool use, reflection, and revision.
Key Insights and Future Directions
What have we learned about orchestrating LLMs for deep research? A few key architectural insights stand out:
- Decompose and conquer: Breaking complex queries into sub-tasks (often via an implicit chain-of-thought) dramatically improves an AI’s ability to handle complexity. It mirrors how experts approach problems and allows focusing on one piece at a time.
- Tools extend the LLM’s capabilities: By integrating search, browsing, and code execution, the LLM overcomes the knowledge cutoff and static nature of its training data. Tools act as the model’s eyes and hands in the real world — fetching up-to-date info and performing precise operations.
- The LLM as an orchestrator: Rather than solving tasks in one go, the LLM’s role is to intelligently orchestrate these steps. This requires a form of meta-reasoning — reasoning about what knowledge is needed and how to get it. The architecture blurs the line between “thinking” and “acting” for the AI, blending them in a loop.
- Reinforcement learning for alignment with reality: RL fine-tuning with outcome-based rewards has proven critical for aligning the agent’s actions with what produces correct, truthful answers in the wild. It imbues the agent with strategic foresight (since it must think ahead to ultimately be correct) and discourages cheats like hallucinating an answer when unsure.
- Emergent research behaviors: Perhaps most inspiring, when you put these pieces together and train at scale, the agent begins to demonstrate behaviors we didn’t explicitly program: it can self-correct, verify facts, and knows when to say “I don’t know.” These are early signs of AI systems developing a form of cognitive self-regulation, guided by the simple objective of being a good researcher.
As LLM research agents become more advanced, we can expect them to tackle increasingly complex tasks: writing detailed literature reviews, conducting meta-analyses of scientific papers, or even helping programmers by researching documentation and code examples. The patterns established by today’s systems will serve as a foundation. OpenAI’s ChatGPT with browsing and code, Google’s Gemini with its integrated tools, and open frameworks from projects like DeepResearcher show a common path forward — one where AI doesn’t just generate text, but actively learns and discovers.
In conclusion, the orchestration of large language models in deep research tasks represents a significant step toward more autonomous and intelligent AI systems. By structuring an LLM to act as a reasoning hub that can plan, search, read, and analyze, we unlock capabilities far beyond what the base model could do alone. It’s a beautiful synergy of symbolic reasoning (plans and tools) and statistical learning (the LLM’s knowledge). We are essentially teaching these models how to think like a researcher: formulate questions, seek evidence, and synthesize answers with warranted confidence. The journey is just beginning, but the progress so far paints an exciting picture of AI that can truly learn anything, anytime, from the world’s knowledge — just like a devoted human researcher, but at digital speed.
References & Further Reading: For those interested in diving deeper, check out OpenAI’s official documentation on the Deep Research mode and the DeepResearcher paper by Zheng et al. (2024), which provides a research-grade framework for training these agents. The Helicone blog on OpenAI Deep Research offers a great overview and comparison to Gemini and others, and James Briggs’ article on LangGraph is an excellent resource on multi-agent workflows. As AI researchers and engineers, it’s time to embrace these orchestrated LLM architectures — the era of deep research AI is here, and it’s transforming how we interact with knowledge.
Get to know the Author:
Karan Bhutani is a Data Scientist Intern at Synogize and a master’s student in Data Science at the University of Technology Sydney. Passionate about machine learning and its real-world impact, he enjoys exploring how AI and ML innovations are transforming businesses and shaping the future of technology. He frequently shares insights on the latest trends in the AI/ML space.